Der IT-Sektor „Cloud“ wächst stetig und bietet Kunden verschiedene Dienstleistungen und somit eine vielfältige Palette an Möglichkeiten. Im Blogbeitrag „Was ist Serverless-Computing?“ haben wir die Begriffe des Serverless-Computing und Möglichkeiten sowie Vor- und Nachteile der Nutzung dieser Dienste beschrieben. Auch sind wir näher auf das Thema AWS Lambda eingegangen. Der nun folgende Artikel beleuchtet, wie Serverless-Computing in der Umgebung der IBM Cloud funktioniert.
Welche Serverless-Computing-Funktionen bietet die IBM Cloud?
Die IBM Cloud bietet eine Function-as-a-Service (FaaS) Lösung namens IBM Cloud™ Functions. Hiermit können Sie, ganz ohne den Einsatz von Serverinfrastrukturen, Anwendungslogiken als Reaktion auf Ereignisse oder direkte Aufrufe von Web- oder Mobilanwendungen über HTTP ausführen. Cloud Functions übernimmt die Systemverwaltung, z. B. das Verfügbarkeitsmanagement und die Wartung, so dass Sie sich als Entwickler auf das Schreiben der Anwendungslogik konzentrieren können. (Quelle)
Wie beginnt man mit IBM Cloud™ Functions?
Die Entwicklung kann auf zwei Arten beginnen:
Cloud Functions UI
Cloud Functions Befehlszeilenschnittstelle (CLI), die mehr Kontrolle über Ihre Bereitstellung und Ihren Betrieb bietet
Beide Wege führen zu den gleichen Ergebnissen. Die Verfahrensschritte sind für beide Wege ähnlich und im Folgenden als Schritt-für-Schritt Anleitung aufgelistet. (Quelle)
Bei der Entwicklung und Ausführung von IBM Cloud™ Functions sind einige typische Schritte zu beachten:
Schritt 1: Erstellen Sie ein IBM Cloud-Konto und loggen Sie sich ein
Schritt 2: Navigieren Sie zum Cloud Functions Dashboard
Schritt 3: Wählen Sie einen Namespace (erforderlich)
Schritt 4: Klicken Sie auf „Start Creating“ > „Quickstart Templates“ und wählen Sie die Vorlage „Hello World“.
Schritt 5: Erstellen Sie ein Paket für Ihre Aktion, indem Sie einen eindeutigen Namen in das Feld „Paketname“ eingeben.
Schritt 6: Wählen Sie eine Laufzeit für Ihre Aktion. Sie können eine Vorschau des Codes für die Beispielaktion in jeder verfügbaren Laufzeit anzeigen, bevor Sie die Vorlage bereitstellen.
Schritt 7: Klicken Sie auf „Bereitstellen“. Sie haben nun eine Aktion erstellt.
Schritt 8: Durch den Aufruf einer Aktion wird die Anwendungslogik, die die Aktion definiert, manuell ausgeführt. Im Bereich „Aktivierungen“ sehen Sie die von der Aktion erzeugte Begrüßung „Hallo Fremder“.
Schritt 9: Optional: Klicken Sie auf „Eingabe ändern“, um die Aktion zu ändern, oderprobieren Sie Ihre eigene Aktion aus.
Schritt 10: Das war schon alles! Um diese Aktion zu bereinigen, klicken Sie auf das Überlaufmenü und wählen Sie „Aktion löschen“.
So funktioniert IBM Cloud™ Functions aus technischer Sicht
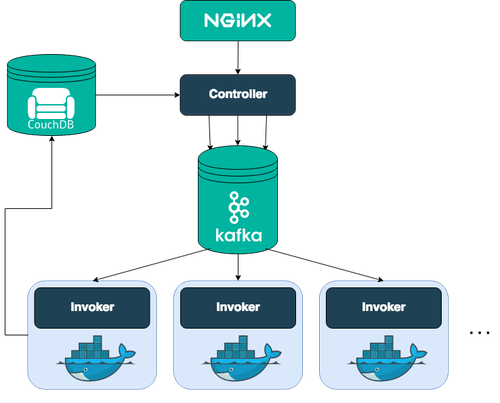
Cloud Functions basiert auf OpenWhisk, einem Open-Source-Projekt, das Komponenten wie NGINX, Kafka, Docker und CouchDB zu einem serverless-ereignisbasierten Programmierdienst kombiniert. (Quelle)
Der erste Einstiegspunkt in das System erfolgt über NGINX, einen HTTP- und Reverse-Proxy-Server. NGINX wird für die SSL-Terminierung und die Weiterleitung entsprechender HTTP-Aufrufe verwendet. NGINX leitet die HTTP-Anfrage an den Controller weiter, die nächste Komponente auf dem Weg durch OpenWhisk.
Der Controller ist eine Scala-basierte Implementierung der eigentlichen REST-API (basierend auf Akka und Spray). Als solcher dient der Controller als Schnittstelle für alles, was Sie tun möchten, einschließlich der Erstellung, Abfrage, Aktualisierung und Löschung von Anfragen für Ihre Entitäten in OpenWhisk und dem Aufruf von Aktionen. Nun prüft der Controller, wer Sie sind (Authentifizierung) und ob Sie die erforderlichen Berechtigungen haben, um das zu tun, was Sie mit dieser Entität tun wollen (Autorisierung). Die Credentials, die in der Anfrageenthalten sind, werden mit der sogenannten Subjects Datenbank in einer CouchDB Instanz abgeglichen. Nachdem der Controller festgestellt hat, dass man authentifiziert und autorisiert ist, die Aktion aufzurufen, lädt er die Aktion aus der Whisks Datenbank in CouchDB.
Der Load Balancer weiß, welche Invoker verfügbar sind und wählt einen von ihnen aus, um die angeforderte Aktion aufzurufen. Der Controller und der Invoker kommunizieren ausschließlich über Nachrichten, die von Kafka gepuffert und persistiert werden. Kafka entlastet sowohl den Controller als auch den Invoker von der Pufferung im Speicher und stellt gleichzeitig sicher, dass die Nachrichten bei einem Systemabsturz nicht verloren gehen.
Um Aktionen isoliert und sicher auszuführen, wird mit Docker für jede aufgerufene Aktion eine selbstgekapselte Umgebung (ein sogenannter Container) eingerichtet. Nach der Erstellung des Containers wird der Code injiziert und dann mit den übergebenen Parametern ausgeführt. Wenn die Ergebnisse zurückgegeben werden, wird der Container zerstört. In dieser Phase können Leistungsoptimierungen vorgenommen werden, um den Wartungsaufwand zu verringern und niedrige Antwortzeiten zu ermöglichen. Nachdem der Invoker das Ergebnis erhalten hat, wird es in der whisks-Datenbank als eine Aktivierung unter der zugewiesenen Aktivierungs-ID gespeichert. Die whisks-Datenbank befindet sich in CouchDB.
Vor- und Nachteile von IBM Cloud™ Functions
Im Allgemeinen sind IBM Cloud™ Functions nützlich für kleinere Aufgaben bei mobilen Anwendungen mit nicht weiterführenden Aufrufen. Vorteile sind hier die Skalierbarkeit, eine einfache Auslösung und die Datei-Validierung. Die IBM Cloud™ Functions eignen sich unter anderem für Unternehmen mit kompakten Prozessen.(Quelle)
Auch wir bei der Libelle IT Group setzen auf die Vorteile der Cloud und stellen Ihnen verschiedene Lösungen zur Verfügung. Nutzen Sie jetzt die Cloud-Editions von Libelle DataMasking (AWS / Microsoft Azure), Libelle SystemCopy (AWS / Microsoft Azure) oder Libelle CloudShadow (IBM Cloud).
Empfohlenener Artikel
30. November 2022Die 12-Faktor-App Teil 3: (Einweggebrauch, Dev-Prod-Vergleichbarkeit, Logs, Admin-Prozesse)