Warum ist die Performance bei der Datenmaskierung wichtig?
Das Ziel der Datenmaskierung ist es, Daten, die als sensibel eingestuft werden, in nicht-produktiven Systemen zu verschleiern, um Risiken zu reduzieren und gesetzliche und Compliance-Anforderungen zu erfüllen. Die Daten werden physisch durch nicht-sensible Daten ersetzt. Diese folgen definierten Mustern, um die Struktur und das Wesen der ursprünglichen Daten beizubehalten, jedoch ohne das Risiko einer tatsächlichen Datenexposition. Anwendung findet dies auf produktionsunterstützenden Systemen für Tests und Entwicklung oder für Data Warehouses und Analysesysteme.
Maskierung - Schritt für Schritt
Die Datenmaskierung erfolgt ad hoc. In der Regel, wenn ein Testsystem mit nicht maskierten Produktionsdaten erstellt oder aktualisiert wird. Unter der Annahme, dass eine Datenbank maskiert wird, könnte man einen vereinfachten Arbeitsablauf der Maskierung in drei Schritten betrachten:
- Lesen von Daten aus der Datenbank
- Verschleiern der Daten
- Verdeckte Daten zurück in die Datenbank schreiben
Bei der Maskierung von einigen tausend Datensätzen ist die Leistung kein Problem. Die meisten Maskierungsprojekte erfordern jedoch die Verschleierung von mehreren Millionen, manchmal sogar Milliarden von Zeilen mit sensiblen Daten. Bei mehr als ein paar Millionen Datensätzen kann die sequentielle Ausführung von Lese-, Verschleierungs- und Schreibvorgängen für jede Zeile Tage, wenn nicht Wochen dauern.
Datenmaskierung funktioniert effizient mit Parallelisierung und Multi-Threading
Libelle hat eine intelligente Multithreading-Architektur implementiert, um die Leistung auf ein absolutes Maximum zu steigern. Datenbanken sind ausdrücklich für die parallele Verarbeitung von Millionen Lese- und Schreibvorgängen ausgelegt. Sequentielle Lese- und Schreibvorgänge an eine Datenbank zu senden ist so, als würde Ihr Lieblings-Online-Händler einen einzigen Lkw betreiben, der jeweils nur eine Kiste zwischen den Zielorten hin und her fährt - unsinnig. Vielmehr kann die Logistikinfrastruktur Tausende Fahrzeuge bewältigen, und jedes Fahrzeug kann Hunderte Kisten transportieren. Das Gleiche gilt für den Prozess der Datenmaskierung.
Die Libelle DataMasking Multi-Threading Architektur
Das folgende Diagramm zeigt, wie Libelle die Multi-Threading-Architektur entwickelt hat und betreibt. Sie ist in die Architektur der Libelle-Plattform integriert, auf der der Libelle DataMasking Server läuft.
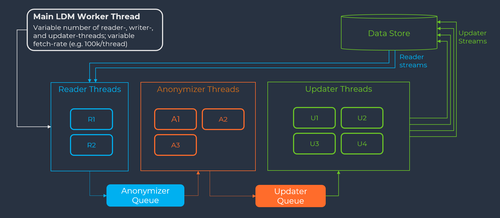
Zu Beginn jeder Ausführung kann der Administrator die Abrufrate einstellen. Standardmäßig ist die Abrufrate auf 100.000 Datensätze auf einmal eingestellt, wobei ein Datensatz typischerweise eine Zeile in einer Datenbank darstellt. Das bedeutet, dass jeder Thread 100k Zeilen enthält.
Die Maskierungskonfiguration enthält bereits die Tabelle und die Felder, die maskiert werden müssen. Mit diesen Informationen beginnen die Reader-Threads, jeweils 100k Datensätze aus der Datenbank zu lesen. Ein guter Ausgangspunkt sind in der Regel zwei Reader-Threads (2RT), die die Daten lesen, in den Maskierungsserver ziehen und die gelesenen Daten in die Anonymizer Queue stellen.
Sobald die Daten in der Anonymizer Queue angekommen sind, werden sie vom Maskierungsserver mit dem/den jeweiligen Algorithmus(n) maskiert, wobei jeder Thread immer noch 100k Datensätze hat. Dabei werden Namen geändert, Nummern neu generiert, Adressen geändert usw. Die Anonymisierung kann mehr Zeit in Anspruch nehmen als das Lesen, so dass in diesem Fall drei Anonymisierungs-Threads (3AT) ein guter Ausgangspunkt sind.
Nachdem jeder Thread in der Anonymizer Queue abgeschlossen ist, gelangen die Daten in die Update Queue. Hier werden die Daten zurück in die Datenbank geschrieben, immer noch mit 100k Datensätzen für jeden Thread. Das Schreiben in die Datenbank kann ressourcenmäßig teurer sein, so dass vier Aktualisierungs-Threads (4UT) ein guter Ausgangspunkt sind.
Die Standardkonfiguration von 2RT / 3AT / 4UT kann auf der Grundlage der individuellen Anforderungen der einzelnen Datenspeicher auf jede gewünschte Anzahl angepasst werden.
Extreme Leistung
Die Maskierung muss so schnell wie möglich abgeschlossen werden, da die Endbenutzer ihr Analyse- oder Testsystem so rasch wie möglich wieder benötigen. Multi-Threading hat einen erstaunlichen Vorteil: Die Arbeitslast kann auf mehrere CPUs und, je nach Datenbank, manchmal sogar auf mehrere Datenbankknoten verteilt werden. Somit kann eine Geschwindigkeit von 100.000 und mehr Update pro Sekunde erreicht werden.
Denken Sie an eine Cloud-Umgebung, in der Sie die Arbeitslast vorübergehend auf größere Maschinen verlagern können. Warum verschieben Sie die Testumgebung nicht vorübergehend auf ein Arbeitstier mit 512 vCPU / 2 TB Speicher in einer öffentlichen Cloud Ihrer Wahl, führen die Maskierung aus und kehren dann zu Ihrem kleineren Testserver zurück?
Weitere Informationen zu Libelle DataMasking
Die Libelle IT Group hat hier mit Libelle DataMasking eine Lösung für die erforderliche Anonymisierung und Pseudonymisierung entwickelt. Konzipiert wurde die Lösung zur Herstellung anonymisierter, logisch konsistenter Daten auf Entwicklungs-, Test- und QS-Systemen über alle Plattformen hinweg.
Die eingesetzten Anonymisierungsverfahren liefern realistische, logisch korrekte Werte, mit denen relevante Geschäftsfälle beschrieben und sinnvoll Ende-zu-Ende getestet werden können. Des Weiteren steht Entwicklern sowie Anwendern eine „saubere“ Datenbasis zur Verfügung, mit der sie sich keine Sorgen um den Datenschutz machen müssen.
Empfohlenener Artikel
Alle Blogartikel